Service vs. Domain
One of our personal challenges with FFLIB has always been the separation between the Service and Domain layers, which we find somewhat artificial. According to the theory, the Service layer is meant to expose API services for a particular object, such as opportunities.
Note: Here, I’m using the term API to represent a service or an internal API that a module exposes, not a REST or SOAP API.
Here’s an example from the Trailhead module:
public with sharing class OpportunitiesService {
public static void applyDiscounts(
Set<Id> opportunityIds,
Decimal discountPercentage)
{Here, the OpportunitiesService class exposes an API to apply discounts to certain opportunities. But we encourage you to pause and think why couldn’t this logic exist in the Domain layer? For example:
//this is the domain layer according to fflib
public class Opportunities {
public static void applyDiscounts(
Set<Id> opportunityIds,
Decimal discountPercentage)
{We can’t think of a reason this logic should sit in a Service layer. In fact, we’d argue for creating a class called OpportunityDiscount that encapsulates all the logic required to calculate discounts. Then, we would place this class in the respective Salesforce DX source folder for that business unit and use case.
The theory on Trailhead tells us that the Domain layer (e.g., the Opportunities class) should only handle logic related to trigger events and input validation. In our opinion, this is an entirely artificial separation. If calculating discounts for opportunities is such an important functionality, why should it be separate from the Domain class?
Also, both classes above are exactly the same. The only difference is in the name. If we add the word “service” to it, it magically becomes a Service class. Without it, it’s a Domain class. Again, in our opinion, this is an artificial separation.
Two points are at the center of this critique. First, the Service vs. Domain pattern does not provide concrete guidance on when to keep logic together, or when to keep it apart. The guidelines provided in this session of are much more straight forward and applicable. As a reminder, a desire to reduce complexity should be the driving force of this question.
Second, FFLIB offers little guidance on where to put business logic. Should business logic reside in the Service layer? Or in the Domain layer? Should it be split between the two (which decreases cohesion)?
For AWAF, we want to provide concrete guidelines that answer three questions:
- What is business logic?
- What is not business logic?
- Where should business logic go?
What is business logic?
Business logic becomes easier to define when we first consider what is not business logic. Here are some examples of non-business logic:
- Retry logic for queueable Apex
- Bypass logic in trigger handlers
- Governor limit logic (e.g., delegating to an async handler when nearing the DML limit)
- Pure database transaction logic (e.g., catching exceptions, retrying, aggregating records into a list)
From these examples, we can deduce that business logic is the logic that our users care about, like, "when an opportunity is closed/won, a default contract should be created." The infrastructure in which that logic runs (whether a trigger, queueable, or platform event) is irrelevant to the business.
Business logic should be written from the inside out
Some schools of thought advocate for creating a clear separation between business and infrastructure logic. For example, in the imperative shell, functional core architecture, business logic is completely decoupled from infrastructure logic, making the business logic easier to test.
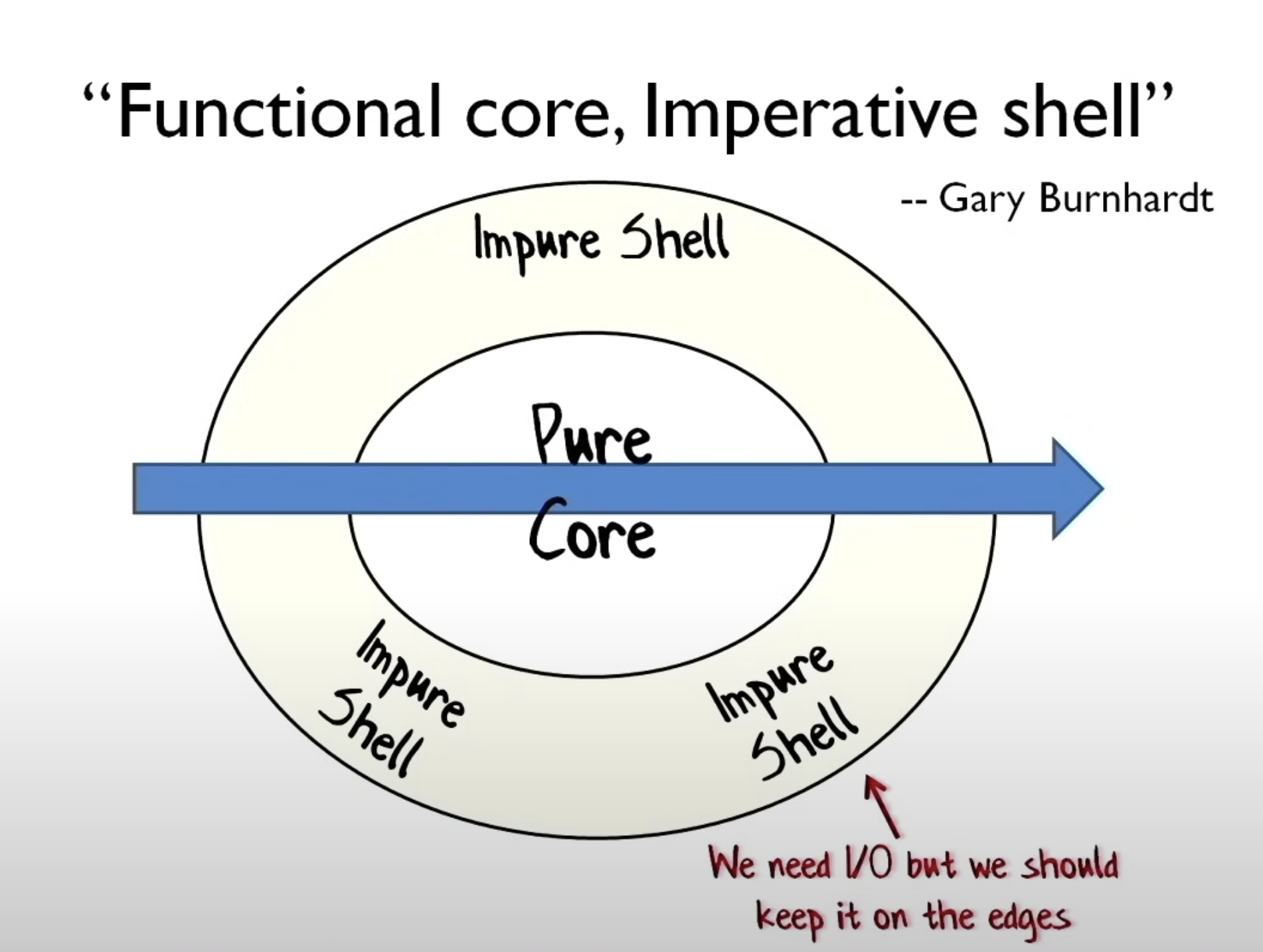
In this approach, when we have a business requirement (like creating a contract for a closed opportunity), we model that logic in a way that’s completely decoupled from external dependencies like the database or governor limits. This layer is called the functional core—it contains the pure business logic that can be easily unit-tested.
Here’s what it might look like:
public class ClosedOpportunity {
public Decision createContract(Opportunity oppty){
if (oppty.StageName == 'Closed Won') {
return Decision.CREATE_CONTRACT;
}
return Decision.DO_NOTHING;
}
public enum Decision {
CREATE_CONTRACT,
DO_NOTHING
}
}Notice how the method createContract simply returns a decision, either "create a contract" or "do nothing." This logic reflects how the business would describe the requirement, without any mention of DML operations or infrastructure concerns. And in fact, it should be incredibly easy to unit-test this.
The imperative shell is then a wrapper class responsible for interacting with the database and other dependencies. It takes the decision from the functional core and performs the actual interactions with the database.
public void createContract(Opportunity oppty) {
ClosedOpportunity.Decision decision = new ClosedOpportunity().createContract(oppty);
if (decision == ClosedOpportunity.Decision.CREATE_CONTRACT) {
// Perform the actual DML operation
} else {
// Do nothing
}
}Again, advocates of this approach argue that the functional core’s purity makes it easier to test and maintain.
However, we aren't huge fans of this approach. The imperative shell is almost a mirror of the functional core, except it handles infrastructure logic. These causes high coupling between the two classes, and adds complexity and maintenance overhead.
So, if we don’t agree with this approach, why spend so much time discussing it? Because we believe one of its core ideas is valuable: we should build business logic from the inside out.
Rather than starting with infrastructure concerns (e.g., triggers or platform events, comparing Trigger.new against Trigger.old, etc.), we should begin by modelling the core logic in a way that’s somewhat agnostic to how it’s called. For example, the method in the functional core accepts an Opportunity object directly—it doesn’t care whether the opportunity came from Trigger.new or a batch class. This is not so different from a recommendation made in this session: aim to create somewhat general-purpose modules, as they are deeper.
Concrete guidelines for business logic
With all this said, let us now give some concrete guidelines as per the AWAF model:
- Always consider building business logic from the inside out. This enables easier testing and reusability.
- Where possible, decouple the business logic from the infrastructure logic by using plain and simple dependency injection. For example, consider injecting a wrapper around the
Databaseclass, so that you can unit-test the pure business logic. - Trigger handler classes are considered infrastructure and should contain only the minimal business logic required to route records to the correct class. The bulk of the logic should be inside “functional core” classes. This ensures that business logic remains reusable, testable, and independent of trigger contexts like trigger.new
- Focus your efforts on identifying where in the Salesforce DX hierarchy a class should be. It should be in a place where its intent, purpose and business value become obvious.
- Where to put business logic should be influenced by a desire to increase cohesion.
In short, rather than prescribing, “business logic should go in this layer because my framework says so,” we encourage you to follow the above principles. They will guide you in making decisions that fit your specific org, team, and use cases.